
Sebbene il termine 5G stia ad indicare la quinta generazione di sistemi di telefonia mobile non si tratta di un semplice evoluzione del 4G come i vari passaggi da 2G (il famoso GSM) a 3G, 4G per finire con il 4,5G ma di qualcosa di diverso, come il passaggio tra Etacs che era ancora analogico, al GSM digitale
A metà dell’800 Maxwell elaborò le prime formule matematiche sull’elettromagnetismo che ampliavano e completavano gli studi di Faraday; Le ricerche di Maxell aprirono la porta a tutta una serie di studi di altri scienziati tra i quali vi era il tedesco Heinrich Hertz che nel 1886 costruì un apparecchio in grado di generare onde relativamente lunghe ed un altro che poteva riceverle.
Hertz si dimostrò scettico sull’utilità pratica del suo strumento dichiarando ” È priva di qualunque uso pratico (…) è soltanto un esperimento che prova come il maestro Maxwell avesse ragione…” e a chi insisteva interrogandolo sul suo punto di vista su ciò che poteva accadere come conseguenza della sua scoperta ribadiva :”Nulla presumo”. Per fortuna non tutti la pensavano così e l’esperimento di Hertz portò alla creazione della radio.
Le onde radio sono una radiazione elettromagnetiche e, queste ultime, sono presenti praticamente ovunque in natura: la stessa luce visibile è una forma di radiazione elettromagnetica, come le microonde, i raggi X e le onde radio.
Ma cosa sono le radiazioni elettromagnetiche?
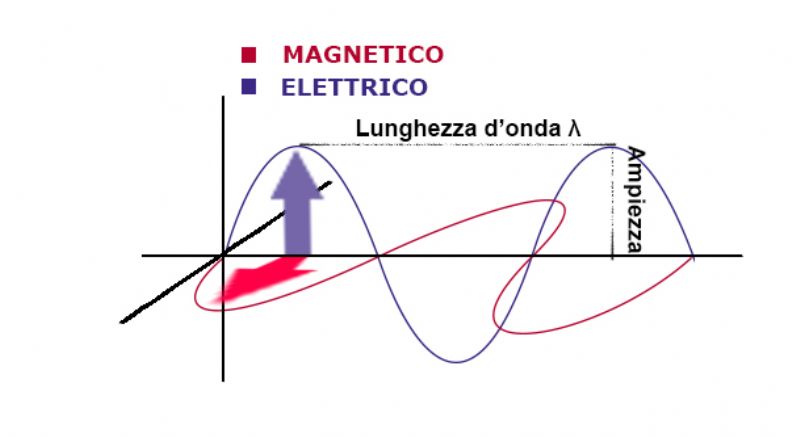
La radiazione elettromagnetica può essere trattata secondo due punti di vista: secondo la teoria ondulatoria e secondo la teoria corpuscolare o quantica. Quella che interessa a noi, in questo momento è la teoria ondulatoria secondo la quale la radiazione elettromagnetica si comporta come un’onda che viaggia alla velocità della luce (c) e può essere descritta in termini della sua lunghezza d’onda λ e della sua frequenza di oscillazione ν dove la lunghezza d’onda è la distanza tra i massimi successivi di un onda, mentre la frequenza (ν) è il numero di cicli completi di un onda che passano per un punto in un secondo e l’unità di misura è chiamata Hertz.
Questi due parametri sono legati dall’equazione: λ = c/ν e da qua ricaviamo che la lunghezza d’onda è inversamente proporzionale alla frequenza ovvero aumenta con il diminuire della frequenza.
Per fare un esempio pratico la luce visibile dall’occhio umano è compresa tra una frequenza che varia dai 400 e 700 nanometri.
Le onde radio hanno una lunghezza che varia dai 10cm ai 10Km, all’interno di questa lunghezza le frequenze che vengono utilizzate per la radiocomunicazione (Tv, Radio, Telefonia mobile, ecc.) va dai 3 kHz e 300 GHz. Fino ad ora, per la telefonia mobile, si sono utilizzate le frequenze che vanno dai 900 Mhz dei 2G (GSM) ai 2600 Mhz dei 4G (LTE) e tutti i telefoni cellulari 4G di ultima generazione sono in grado di passare da una frequenza all’altra a seconda della copertura. Questo tipo di frequenze hanno delle lunghezze d’onda che non vengono assorbite facilmente nel loro cammino da ostacoli di medie dimensioni, come le case o gli alberi e possono essere trasmesse a distanza perché (come dimostrato da Marconi) vengono riflesse dagli strati ionizzati dell'atmosfera. Sebbene tecnicamente il 4G LTE sarebbe in grado di velocità fino a 300 Mbps, in realtà siamo nell’ordine di 5-12 Mbps in download e 2-5 Mbps in upload, con picchi che scendono tra i 5 e gli 8 Mbps (alcuni test di operatori di telefonia italiani nel 2014 sono arrivati oltre i 30Mbps ma erano solo test in condizioni ottimali).
Come potrà allora il 5G riuscire a superare le velocità attuali?
Immaginiamo le frequenze come un triangolo equilatero con la punta verso il basso, le telecomunicazioni utilizzano le frequenze che si trovano vicino alla punta mentre in alto (nella parte larga) sopra i 24Ghz non vi è praticamente traffico; questo è dovuto al fatto che le onde a quella frequenza hanno lunghezza molto corta e quindi non riescono a superare facilmente gli ostacoli.
La tecnologia 5G utilizzerà tre spettri di frequenza: dai 694-790 Mhz, 3,6 e 3,8 GHz per finire con 26,5 e 27,5 GHz.
Nel primo range di frequenza fanno parte anche le trasmissioni di alcuni canali della televisione digitale ed è uno dei motivi (ve ne sono anche altri come il tipo di compressione del segnale), che si dovranno cambiare i decoder dei televisori non predisposti; questo tipo di frequenza è necessario dato che riesce a passare attraverso gli ostacoli normali (alberi, case, ecc.) pur potendo trasmettere parecchie informazioni. Il secondo gruppo di frequenze offre una buona velocità di connessione ma è più soggetta ad essere bloccata dagli ostacoli. Questo lo possiamo verificare anche nelle nostre case: i router casalinghi utilizzano le frequenze 2,4 e 5Ghz, se utilizzo i 5Ghz avrò una “maggiore” velocità nella comunicazione con il router dato che maggiore la frequenza, maggiore è la velocità con cui trasmette i dati, ma il segnale è “più debole”. L’ultimo gruppo di frequenze hanno una lunghezza d’onda più corta delle precedenti e quindi una frequenza maggiore il che si traduce nella possibilità di trasmettere molto velocemente i dati ma che gli ostacoli sul cammino possono bloccare o diminuire di molto il segnale.
La prima conseguenza dell’utilizzo di queste frequenze è quello che per un utilizzo ottimale del 5G sarà necessario aumentare la copertura delle celle presenti sul territorio e che non sempre sarà possibile utilizzare il 5G al massimo delle sue potenzialità. I più penalizzati saranno, quasi sicuramente, gli utenti che vivono nelle zone rurali nelle quali è più difficile posizionare una grande quantità di ripetitori rispetto che nelle città e, se sono presenti anche alberi, difficilmente sarà possibile avere la copertura sopra i 26 Ghz se si è troppo lontani dai ripetitori dato che l’acqua presente nel tronco e nelle foglie tende ad assorbire le onde più facilmente. È probabilmente la banda che verrà utilizzata maggiormente dagli smartphone nel primo periodo di diffusione del 5G sarà quella compresa tra i 3,6 ed i 3,8 Ghz che offrirà comunque una velocità maggiore del 4,5G.
Il fatto che il 5G utilizzi una frequenza così altra ha destato molte preoccupazioni e leggende metropolitane tra gli internauti tanto da creare veri e propri comitati contro l’utilizzo di questa tecnologia. In realtà non succederà, come sostengono molti, che vi sarà un abbattimento indiscriminato di alberi per dare la possibilità al segnale di arrivare facilmente, ma più probabilmente in futuro nascerà una nuova forma di digital divide tra le zone più o meno servite a causa delle pesanti norme esistenti.
Un'altra delle paure infondate che sono nate è che l’utilizzo delle frequenze così alte possano essere dannose per l’uomo e che le onde del 5G possa cuocerci come i forni a microonde.
In realtà è già da parecchi anni che si parla di eventuali danni che i campi elettromagnetici (in particolare l’uso del cellulare) possono generare nell’uomo ma, malgrado quello che dicono i giudici con una recente sentenza della cassazione, non vi sono prove scientifiche di questo e nessuno scienziato ha potuto portare una dimostrazione che questo sia vero.
È vero che i campi elettromagnetici generano calore (come nei forni a microonde) ma questo tipo di onde hanno lunghezze d'onda che vanno da 1 mm a 30 cm, uno spettro che è sotto quello delle radiazioni infrarosse. Tra le organizzazioni internazionali deputate al monitoraggio della salute delle persone solamente l'Agenzia Internazionale per la Ricerca sul Cancro (IARC) ha classificato i campi elettromagnetici a radiofrequenza (CRF) come cancerogeni di gruppo 2B (nella stessa classifica risultano, ad esempio l’estratto di foglie di Aloe e l’estratto di kava), e considera limitato il grado di correlazione tra l'utilizzo intensivo di telefoni cellulari e lo sviluppo di tumori cerebrali, mentre lo considera non dimostrato scientificamente per tutti gli altri tipi di cancro. Bisogna in fine considerare che la tecnologia 5G si basa su antenne adattative che sono caratterizzate non più da una emissione costante di potenza in tutte le direzioni, ma da una emissione “adattativa” in base al numero di utenze da servire, dalla loro posizione e dal tipo di servizio.
Del 5G si è detto e si dirà molto, ma certamente rappresenta un passo avanti nelle telecomunicazioni soprattutto per l’internet delle cose, ma la preoccupazione vera è che questa nuova tecnologia a causa delle sue limitazioni andrà ad aumentare il gap tecnologico che esiste anziché diminuirlo.
Il Consiglio Europeo, dal canto suo, è convinto che la nuova tecnologia favorirà l'innovazione dei modelli commerciali e dei servizi pubblici ma che in paesi come l’Italia, con norme molto restrittive sulla radioprotezione, c’è il rischio di rallentare lo sviluppo delle nuove reti ed invita i paesi membri ad adottare le linee guida dell’ICNIRP (International Commission on Non Ionizing Radiation Protection) che rappresentano il massimo riferimento scientifico del settore.
BIBLIOGRAFIA
Rif.: Ian Stewart, “Le 17 equazioni che hanno cambiato il modno”, Frontiere, edizione 2019, pp.267-287
Rif.: IARC, https://monographs.iarc.fr/agents-classified-by-the-iarc/
(Ultima
consultazione marzo 2020)
Rif.: O.M.S. : https://www.who.int/en/news-room/fact-sheets/detail/electromagnetic-fields-and-public-health-mobile-phones
(Ultima
consultazione marzo 2020)
Rif.: Camera dei Deputati Servizio Studi: https://www.camera.it/temiap/documentazione/temi/pdf/1105154.pdf
(Ultima
consultazione marzo 2020)
Rif: Arpa Emilia-Romagna: https://www.arpae.it/dettaglio_generale.asp?id=4149&idlivello=2145
(Ultima
consultazione marzo 2020)

Il secondo decennio del 21 secolo è appena iniziato e pochi si ricordano che solamente vent’anni fa abbiamo rischiato una piccola regressione digitale.
Questa riflessione nasce da un post che sta girando da qualche giorno sui maggiori social network e programmi di IM che avverte che “Quando scriviamo una data nei documenti, durante quest’anno è necessario scrivere l’intero anno 2020 in questo modo: 31/01/2020 e non 31/01/20 solo perché è possibile per qualcuno modificarlo in 31/01/2000 o 31/01/2019 o qualsiasi altro anno a convenienza. Questo problema si verifica solo quest’anno. Stare molto attenti! Non scrivere o accettare documenti con solo 20. Fate girare questa utile informazione”.
A prescindere dal fatto che in tutti i documenti legali è buona norma (quando non obbligatorio) usare la data in formato esteso, tutti i documenti che prevedono una registrazione prevedono anche una datazione estesa al decennio, fin dai tempi del Millennium Bug.
Ma cosa è stato questo Millennium Bug che tanto ha spaventato alla fine del 1999 il mondo informatico e che è passato senza troppi problemi tanto che oggi c’è chi (i complottisti esistono sempre!) crede che non sia mai stato un reale problema ma un’invenzione atta a far spendere solti alle aziende, agli stati ed ai singoli utenti?
Spieghiamo subito che il termine Bug, in informatica, identifica un errore di programmazione e nel caso del Y2K (come veniva chiamato il Millenium Bug) non si trattava di un errore di programmazione ma di una scelta dettata dalle necessità: all’inizio dell’era informatica e dei personal computer la memoria rappresentava una risorsa così, quando si scrivevano le date, per gli anni si pensò di utilizzare solamente le ultime due cifre che componevano l’anno e non tutte e quattro così 1972 si scriveva 72.
Ma cosa sarebbe successo al cambio di data dalla mezzanotte dal 31 dicembre 1999 al 1º gennaio 2000 nei sistemi di elaborazione dati? Il cambio di millennio avrebbe portato a considerare le date 2000 come 1900 e i problemi che si presentavano erano parecchi, dal valore degli interessi maturati alle date dei biglietti aerei, dal noleggio di automobili ai dati anagrafici dei comuni, dai possibili blocchi delle centrali elettriche alla paura di disastri nucleari.
Per rendere un’idea del panico che venne propagato basta pensare che negli stati uniti vi fu un aumento dell’acquisto di armi e che la stessa unione europea istituì una commissione per l’analisi dei rischi dell Y2K (https://.cordis.europa.eu/article/id/13568-commissions-analysis-of-the-y2k-problem).
Oggi sappiamo che il problema del Millenium Bug era noto da tempo ad ingegneri e programmatori, molto prima che diventasse un problema mediatico, e che si iniziò a lavorare per evitarne le catastrofiche conseguenze.
La Microsoft con i suoi sistemi operativi Windows95 e Windows98 era preparata e le patch (una porzione di software progettata appositamente per aggiornare o migliorare un determinato programma) che vennero distribuite furono pochissime, non lo stesso per il vecchio window 3.11 che stava in quel periodo terminando la sua vita operativa e che dovette subire parecchi aggiornamenti; i Bios dei computer vennero aggiornati (quando non lo erano già), mentre per i sistemi Linux non si presentarono problemi.
Dire che però tutto filò liscio come l’olio non è esatto, alcuni problemi vi furono e se non diventarono tragedie fu solo perché l’allerta data permise di avere del personale preparato allo scattare della mezzanotte.
Infatti se alcuni problemi come accadde nello United States Naval Observatory che gestisce l’ora ufficiale del paese e sul Web segnò come data il 1 gennaio 1900, o del cliente di un negozio di noleggio video dello stato di New York si trovò sul conto $ 91.250, possono essere considerati fastidiosi in altri casi si rischiò la catastrofe: la centrale nucleare di Onagawa ebbe qualche problema di raffreddamento che scatenò l'allarme 2 minuti dopo mezzanotte, egli Stati Uniti, il sistema di elaborazione dei messaggi della Guardia costiera venne interrotto, alle Hawaii vi furono interruzioni di corrente.
Più tragico fu quanto accadde a Sheffield, nel Regno Unito, dove ci furono valutazioni errate del rischio per la sindrome di Down inviate a 154 donne gravide e vennero effettuati due aborti come risultato diretto del Y2K (dovuto ad un errore di calcolo dell'età della madre), mentre quattro bambini affetti da sindrome di Down sono nati da madri a cui era stato detto che si trovavano nel gruppo a basso rischio ovvero che le possibilità che succeda una cosa del genere era pari a zero.
A vent’anni di distanza possiamo dire che se il Millenium Bug non ha causato danni catastrofici non fu perché il problema non esisteva o era una bufala, ma perché, seguendo il principio di precauzione, sotto spinta del governo americano che aveva riconosciuto che un singolo governo non sarebbe riuscito a intervenire in prima persona ovunque fosse stato necessario e che il rischio potenziale era troppo elevato per poterlo ignorare, aveva coinvolto tutta la società e altri stati tramite un sistema di cooperazione: era impossibile stabilire a priori quali e quanti danni potevano essere arrecati quindi le istituzioni, mentre si preparavano per ogni evenienza, dovevano informare il pubblico sui rischi, e mettere pressione alle aziende affinché iniziassero una politica per evitare i danni del Y2K.
Anche se non tutti i governi investirono nello stesso modo (l’Italia fu il fanalino di coda nell’Eurozona) la comunicazione e l’allarme di massa aveva funzionate e man mano che si procedeva l’aggiornamento dei software e dei Bios, il rischio si riduceva.
Oggi lo stesso tipo di allarme che vent’anni fa venne dato per il Millenium Bug viene dato per il riscaldamento globale ed il cambiamento climatico: dopo che i tecnici del settore (scienziati, fisici, climatologi, ecc.) hanno per devenni avvertito dei rischi intrinsechi derivati dal climate change anche nell’opinione pubblica si sta sviluppando la preoccupazione per un simile futuro.
Ma mentre per l’Y2K le preoccupazioni erano più tangibili ed economicamente capibili quali il pagamento degli interessi sulle azioni, la sicurezza dei sistemi di difesa statali, la sicurezza dei voli o il corretto funzionamento delle centrali nucleari, per il cambiamento climatico i problemi sono più astratti o a più lunga scadenza e lontani dalla reale percezione.
Se si considerasse il problema del cambiamento climatico come fu considerato alla fine del XX secolo il Millenium Bug sarebbe forse più semplice affrontare risolvere il problema.



